
Are we really only going to talk about one issue?
Please, that’s tedious, leaves you open to some well deserved ribbing, and it’s how Prohibition was passed (I think we’ve all learned from that mistake). Like most of us are wont to do in real life let us jump from subject to subject, share stories, describe our dreams and brilliant ideas that only an ample amount of drinking would allow us to divulge and share with another. That’s what this post is and, similarly to a regular conversation, feel free to change the subject and browse to another more beer-centric posting, whether through poking around or following one of several links sprinkled through the text (here’s an interesting tie-in with beer and the Dutch).
I don’t know about you but after a six pack (or six posts in this case) I usually deem myself witty, engaging, and a purveyor of interesting stories and amusing anecdotes. I become loquacious and expansive in my insightful commentary. It is also clear that those around me share this outlook, that they are more easily swayed by my charm which I normally, responsibly, and modestly keep at bay for fear of misusing its power. Dare I say that the barriers of language appear to melt away and those fortunate enough to be present in my company communicate as if by thought alone with words discarded nearly as soon as they’re spoken, disappearing leaving only the meaning behind.
But in recent months I’ve encountered an obstacle: actually living abroad. The mind meld I have grown accustomed to has been more difficult to come by. Forget for a moment that the Dutch all speak English (and without the unnecessary shithead attitude so finely cultivated by the French), which helps lighten the burden and ensures some exchange of earth shattering insights, one cannot help but feel bad that these people are not more fully exposed to my genius.
There is no off position on the genius switch. - David Letterman
It turns out that language remains a necessary bridge. I cannot bear the thought of withholding from these good people any longer. It is time I make a stronger effort at making myself understandable more completely and attempt to meet the adorably accented people of the Netherlands halfway.1 After all, the Dutch founded NYC, make damn good beer themselves, & having recently/temporarily/in-denial-about-the-whole-finality-of-the-prospect relocated to the land of various combinations of smoking and breakfast pastries I sorta, kinda, wanna, needta do this.
The objective: to learn some of the language and a bit about contemporary Dutch life. Where to turn? How about that item that was nearly killed off by the Internet: the newspaper? I’m in a particular part of the country, which translated to American-ese means “not in Amsterdam”, and I wanted to take that into consideration. Why not use another resource, one that replaced an actual internet casualty: Wikipedia.
Regional Dutch newspapers:
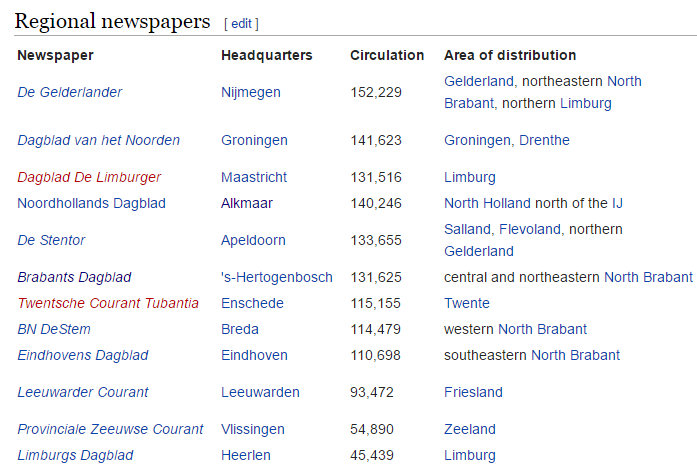
Data Source: Wikipedia
I volunteered one of the above publications to be my vic-, source, and proceeded to pull three front page stories each day, 2-3 times a day, for 4 weeks. The idea was to capture all article text plus some metadata characteristics: date, time, subject classification, and map coordinates where applicable.
As Easy as 1-2-3 (een-twee-drie)?
Simple and too easy? Not completely. There was a good amount of legwork needed. My three-pronged approach to this exercise: word count, bigrams, and term frequency - inverse document frequency (tf-idf). I thought each of these methods would be helpful in finding out more about Dutch and possibly where to start with the language. But before all that I would need to identify stop words.
Stop words are typically the most common words in use over a collection of documents. They are neither surprising in their frequency nor very informative when it comes to recognizing subjects covered. They are of course critical to being understood in normal communication, being the glue that helps string words into sentences (conjunctions, prepositions, and pronouns). The purpose for my identifying Dutch stop words was thus two-fold: to use them as a screen to get to the more interesting words and to keep them around for my own elucidation. While not computationally interesting they could still prove to be a meaningful resource to my learning ambitions.
Where to find stop words? AskJeeves! Na, I’m just kidding. I asked Uncle Google, of course. I thought that I may get an English list of words and translate those into Dutch, but that turned out to be unnecessary. Instead, I took three results from the first search page returned, made a superset of the words from each list, and then had something to screen against.2

Top-10 Stop Words
| term | translation | count |
|---|---|---|
| de | the | 2481 |
| van | from | 1078 |
| het | the | 1063 |
| een | a | 923 |
| in | in | 861 |
| en | and | 615 |
| op | on | 544 |
| is | is | 435 |
| dat | it | 403 |
| te | too | 324 |
For those who’ve done the “Hello world” of big data you can anticipate my next steps. Get a word count across all articles, filter out stop words, and sort in descending order of frequency. I figured the top 50-100 words would be a strong place to start for any future flash cards, at least before the Internet destroys them as well.
Though I want to be absolutely clear about two things: this is NOT big data AND I know that. I simply wanted an excuse to get some more practice with Spark and running Vagrant (partial nerd talk for data tools).
Top-10 Non-Stop Words
| term | translation | count |
|---|---|---|
| politie | police | 152 |
| bosch | bosch | 149 |
| den | pine | 138 |
| tilburg | tilburg | 107 |
| uur | hour | 91 |
| volgens | according to | 87 |
| jaar | year | 76 |
| mensen | people | 67 |
| gaat | going | 62 |
| man | man | 51 |

Hello World 2, or better yet… Hallo Wereld Twee
Single words were a good start but how about something a bit more interesting, perhaps bigrams. It’d be nice to start stringing words together, especially inspired by an authoritative source.
The process was similar to the above with the obvious addition of taking two words and punctuation into consideration. We only string two words together that are within the same sentence. It would be troublesome to take the last word of one sentence and combine it with the first word of the following sentence. That would result in some odd, though perhaps poetic & deep combinations. Maybe an exercise for another time.
Top-10 Bigrams
| terms | translation | count |
|---|---|---|
| van de | of the | 274 |
| in de | in the | 227 |
| de politie | the police | 145 |
| op de | on the | 141 |
| den bosch | bosch | 118 |
| van het | from the | 115 |
| in het | in the | 102 |
| aan de | to the | 86 |
| van een | of a | 77 |
| voor de | for the | 73 |

TF-IDF:
The final approach covered was yet one step of sophistication further but still a simple concept. We wish to identify words that are often used but balance that out by overly common words that appear in many articles. For instance, we would expect large counts for stop words but if we had a way for penalizing words as common as these we should be able to find article-specific interesting terms.
An example of how this works will go a long way to explaining its power. Suppose three articles with the following words:
| article | beer | hops | malt | ipa | stout |
|---|---|---|---|---|---|
| 1 | 3 | 4 | 0 | 2 | 0 |
| 2 | 5 | 2 | 1 | 3 | 0 |
| 3 | 2 | 1 | 1 | 0 | 2 |
To determine the importance of a term using tf-idf we will need to first count three things: the number of times a word appears in a document/article, the total of documents the term appears in, and the total number of documents. Lastly we will combine these counts so as to get a final score (the higher the more important the term). Let us take the term “beer” which you may intuitively be able to see, forgive me for saying it, is not important in this data set, since it appears in each document.
document: 2
term: “beer”
tf: 5
idf: 3/3 = 1 (numerator: # of all docs, denominator: # of docs “beer” appears in, NOT using log for simplicity)
tf-idf: 5 * 1 = 5
Now let us look at “stout”. It appears just twice and in only one article but perhaps you can see where this is going and also intuit that “stout” says more in this collection than the more common “beer”.
document: 3
term: “stout”
tf: 2
idf: 3/1 = 3 (numerator: # of all docs, denominator: # of docs “stout” appears in, NOT using log for simplicity)
tf-idf: 5 * 3 = 15
Hopefully the above examples help to highlight how the process works in identifying key terms for each article, or day, or whatever your choice of unit.
Top-10 tf-idf
World Cloud at Top of Post (with apologies to Kyle at Data Skeptic)
| term | translation | score |
|---|---|---|
| weekmarkten | weekly markets | 0.455494961 |
| turkse | Turkish | 0.420251094 |
| lintjes | ribbons | 0.39047604 |
| jongeren | youth | 0.370535377 |
| autobranden | vehicle fires | 0.369480315 |
| groei | growth | 0.326314964 |
| yenice | yenice | 0.323526478 |
| psv | pSV | 0.318184196 |
| hoorn | Horn | 0.312658317 |
| volkel | volkel | 0.312110305 |
Conclusion
How far along has this exercise gotten us to deciphering Dutch? I took some random sentences and ran them against our numerous word collections to get an idea. Let’s just say it wasn’t pretty and that maybe I need more tijd en werk.3 The next thought was to translate the respective article titles to see if there was any better luck. In een werd: nee.4
Being infinitely clever (if I do say so myself5) I looped through the articles and took a count of matched words in order to determine the article with the highest percentage rate of translate-able terms. The winner among my pretties had a word percentage match of 64%. Below is a line-by-line breakdown of the original text, my ham handed efforts, and Uncle Google’s take, which isn’t exactly fair since he’s had more practice (or is it “she”; is Google a woman, just like G-d?).
| text | one klutz’s efforts | Mr. Show-Off’s take |
|---|---|---|
| In een woning aan de Blazeveldweg in het gebied de Noenes bij Haaren is maandag een overleden vrouw aangetroffen | in a house to the Blazeveldweg in the gebied the Noenes at Haaren is maandag a overleden woman aangetroffen | In a property to the Blaze Veldweg in the Noenes area at Haaren Monday found a deceased woman |
| Volgens de politie zijn er geen aanwijzingen dat de vrouw door een misdrijf om het leven is gekomen | according to the Police his there no aanwijzingen that the woman by a misdrijf to the leven is gekomen | According to the police , there are no indications that the woman was killed by a crime |
| Omdat de politie echter toch een misdrijf niet wil uitsluiten, wordt uitgebreid onderzoek gedaan naar de doodsoorzaak | because the police echter nevertheless a misdrijf not want uitsluiten, is uitgebreid research gedaan to the doodsoorzaak | However, because the police do not want to exclude a crime , extensive research into the cause of death |
| Melding Een ambulance ging rond 10.30 uur al op de melding af van de Blazeveldweg | Melding a ambulance went around 10.30 hour already on the melding down of the Blazeveldweg | Notification An ambulance was already on the alert around 10:30 on the Blaze Veldweg |
| Destijds was het volgens de politie nog niet duidelijk wat er aan de hand was | Destijds was the according to the Police not yet duidelijk What there to the hand was | At the time , according to the police yet clear what was going on |
| Rond 12.30 uur meldt zij dat ze de vrouw hebben aangetroffen. | around 12.30 hour reports they it she the woman have aangetroffen. | Around 12:30 pm they reported that they found the woman. |
I’m cleary not going to become fluent just yet with the work to date, though a bit more macabre. I suppose the best I could hope for is some sort of beautiful Dutchlish monster. However, it is a start and that was my general intention. My newly acquired vocabulary will get me into the purgatory of language understandability, and some awkward conversations apparently, but being out of touch will have to take a back seat to my also being out of time.
Left Out
- Mapping locations of news stories to review geographical/temporal/subject locations or trends.
- Clustering of news stories.
- Sentiment Analysis - should be a bit odd for news articles, but potentially interesting.
- Comments/Tweets - perhaps more appropriate for SA
- Classification - based on the findings, some possible examples would have been for determining articles related to traffic (“bus”), crime (“politie”), or sports (“PSV”); could have implemented bag of words.
All of the above, and more, can be performed on any number of text-based data sets. Look out for most of these to begin appearing in the beer posts to come.
Notes
1 Honestly, have a Dutch person speak to you in English; more than half the time it is adorable. ↩
2 Sources listed below with identified contacts:
- http://snowball.tartarus.org/algorithms/dutch/stop.txt; http://www.patrickmileswriter.co.uk/ \ mail@patrickmiles.co.uk
- http://www.ranks.nl/stopwords/dutch; damian@ranks.nl
- http://www.damienvanholten.com/blog/dutch-stop-words/; http://twitter.com/damienvanholten ↩
3 time and work ↩
4 In a word: oh, hell no!4a ↩
4a Just a little American exageration. ↩
5 What? You weren’t going to. ↩
Tools
- PySpark via Vagrant from Berkely by way of edX; https://twitter.com/atalwalkar
- Sync folders in Vagrant; https://twitter.com/vagrantup
- Create gif; gifmaker.me
- Word cloud at http://www.wordle.net/advanced
Techniques
- https://spark.apache.org/docs/1.2.0/programming-guide.html; https://twitter.com/ApacheSpark
- http://www.mccarroll.net/blog/pyspark2/; esp for bigram
- tf-idf w/sklearn; http://www.markhneedham.com/blog/2015/02/15/pythonscikit-learn-calculating-tfidf-on-how-i-met-your-mother-transcripts/; https://twitter.com/markhneedham