import csv, os, json
import numpy as np
import pandas as pd
print pd.__version__
from datetime import datetime
from collections import Counter, defaultdict
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
%matplotlib inline
0.18.0
pull tw [ggg1]
ingest tw [ggg2]
tweets_data = []
with open('data/kov_ward_tweets.txt', 'r') as f:
for line in f:
try:
tweet = json.loads(line)
tweets_data.append(tweet)
except:
continue
print len(tweets_data)
74902
convert to DF
tweets_df = pd.DataFrame(tweets_data)
tweets_df.created_at = pd.to_datetime(tweets_df.created_at)
tweets_df.sort('created_at', inplace=True)
tweets_df = tweets_df[tweets_df.created_at.notnull()]
tweets_df.drop_duplicates(subset='id_str', inplace=True)
tweets_df.reset_index(drop=True, inplace=True)
print tweets_df.dtypes
print tweets_df.shape
tweets_df.tail()
contributors object
coordinates object
created_at datetime64[ns]
entities object
extended_entities object
favorite_count int64
favorited bool
geo object
id int64
id_str object
in_reply_to_screen_name object
in_reply_to_status_id float64
in_reply_to_status_id_str object
in_reply_to_user_id float64
in_reply_to_user_id_str object
is_quote_status bool
lang object
metadata object
place object
possibly_sensitive object
quoted_status object
quoted_status_id float64
quoted_status_id_str object
retweet_count int64
retweeted bool
retweeted_status object
source object
text object
truncated bool
user object
dtype: object
(74702, 30)
| contributors | coordinates | created_at | entities | extended_entities | favorite_count | favorited | geo | id | id_str | ... | quoted_status | quoted_status_id | quoted_status_id_str | retweet_count | retweeted | retweeted_status | source | text | truncated | user | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 74697 | None | None | 2016-11-20 23:58:49 | {u'symbols': [], u'user_mentions': [{u'indices... | NaN | 3 | False | None | 800488602656444417 | 800488602656444417 | ... | NaN | NaN | NaN | 1 | False | NaN | <a href="http://twitter.com/download/iphone" r... | Say what you want about @andreward but make su... | False | {u'follow_request_sent': False, u'has_extended... |
| 74698 | None | None | 2016-11-20 23:59:14 | {u'symbols': [], u'user_mentions': [{u'indices... | NaN | 0 | False | None | 800488704703860736 | 800488704703860736 | ... | NaN | NaN | NaN | 1 | False | {u'contributors': None, u'truncated': False, u... | <a href="http://twitter.com/download/iphone" r... | RT @GarethADaviesDT: Jerry Izenberg tells me s... | False | {u'follow_request_sent': False, u'has_extended... |
| 74699 | None | None | 2016-11-20 23:59:31 | {u'symbols': [], u'user_mentions': [{u'indices... | {u'media': [{u'source_user_id': 239159456, u's... | 0 | False | None | 800488776401240064 | 800488776401240064 | ... | NaN | NaN | NaN | 5 | False | {u'contributors': None, u'truncated': False, u... | <a href="http://twitter.com/download/android" ... | RT @Shady__007: Was good to bump into the one ... | False | {u'follow_request_sent': False, u'has_extended... |
| 74700 | None | None | 2016-11-20 23:59:35 | {u'symbols': [], u'user_mentions': [{u'indices... | NaN | 0 | False | None | 800488794453639168 | 800488794453639168 | ... | NaN | NaN | NaN | 10 | False | {u'contributors': None, u'truncated': True, u'... | <a href="http://twitter.com" rel="nofollow">Tw... | RT @JCGBoxing: Basta de #KovalevWard por un ra... | False | {u'follow_request_sent': False, u'has_extended... |
| 74701 | None | None | 2016-11-20 23:59:43 | {u'symbols': [], u'user_mentions': [{u'indices... | NaN | 0 | False | None | 800488827278258177 | 800488827278258177 | ... | NaN | NaN | NaN | 3 | False | {u'contributors': None, u'truncated': False, u... | <a href="http://twitter.com/download/android" ... | RT @IzquierdazoBox: "Ward tiene un gran futuro... | False | {u'follow_request_sent': False, u'has_extended... |
5 rows × 30 columns
- plot on ts [ggg2]
- identify rd’s & rest [ggg2]
- export rest tw with regex scores [ggg2]
print tweets_df.created_at.min()
print tweets_df.created_at.max()
2016-11-16 00:41:50
2016-11-20 23:59:43
create new user_ DF fields
user_fields = ['created_at', 'description', 'followers_count', 'friends_count', 'geo_enabled',
'location', 'name', 'screen_name', 'statuses_count', 'time_zone', 'utc_offset']
user_fields_df = ['user_'+i for i in user_fields]
print user_fields_df
['user_created_at', 'user_description', 'user_followers_count', 'user_friends_count', 'user_geo_enabled', 'user_location', 'user_name', 'user_screen_name', 'user_statuses_count', 'user_time_zone', 'user_utc_offset']
tweets_df = pd.concat([tweets_df,pd.DataFrame(columns=user_fields_df)])
tweets_df.columns
Index([ u'contributors', u'coordinates',
u'created_at', u'entities',
u'extended_entities', u'favorite_count',
u'favorited', u'geo',
u'id', u'id_str',
u'in_reply_to_screen_name', u'in_reply_to_status_id',
u'in_reply_to_status_id_str', u'in_reply_to_user_id',
u'in_reply_to_user_id_str', u'is_quote_status',
u'lang', u'metadata',
u'place', u'possibly_sensitive',
u'quoted_status', u'quoted_status_id',
u'quoted_status_id_str', u'rest_period',
u'retweet_count', u'retweeted',
u'retweeted_status', u'source',
u'text', u'truncated',
u'user', u'user_created_at',
u'user_description', u'user_followers_count',
u'user_friends_count', u'user_geo_enabled',
u'user_location', u'user_name',
u'user_screen_name', u'user_statuses_count',
u'user_time_zone', u'user_utc_offset'],
dtype='object')
def user_info(row, field):
try:
return row[field]
except:
return None
for f,df in zip(user_fields, user_fields_df):
tweets_df[df] = tweets_df.user.apply(user_info, field=f)
tweets_df.user_created_at = pd.to_datetime(tweets_df.user_created_at)
print tweets_df.dtypes
tweets_df[user_fields_df].head()
contributors object
coordinates object
created_at datetime64[ns]
entities object
extended_entities object
favorite_count float64
favorited object
geo object
id float64
id_str object
in_reply_to_screen_name object
in_reply_to_status_id float64
in_reply_to_status_id_str object
in_reply_to_user_id float64
in_reply_to_user_id_str object
is_quote_status object
lang object
metadata object
place object
possibly_sensitive object
quoted_status object
quoted_status_id float64
quoted_status_id_str object
rest_period float64
retweet_count float64
retweeted object
retweeted_status object
source object
text object
truncated object
user object
user_created_at datetime64[ns]
user_description object
user_followers_count int64
user_friends_count int64
user_geo_enabled bool
user_location object
user_name object
user_screen_name object
user_statuses_count int64
user_time_zone object
user_utc_offset float64
dtype: object
| user_created_at | user_description | user_followers_count | user_friends_count | user_geo_enabled | user_location | user_name | user_screen_name | user_statuses_count | user_time_zone | user_utc_offset | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-05-30 18:13:42 | 123 | 102 | True | Rico | Deef_djam | 9005 | London | 0.0 | ||
| 1 | 2011-05-30 18:13:42 | 123 | 102 | True | Rico | Deef_djam | 9005 | London | 0.0 | ||
| 2 | 2015-11-15 21:59:32 | amosc: derreberrygirl 🎓SEN17RS🤘🏽 | 150 | 130 | True | New Orleans, LA | Queen Derreberry | _derreberry | 2177 | None | NaN |
| 3 | 2012-09-12 23:56:32 | #IRONADDICT #MARTIALARTIST\n#BOXING \n@TOPCLAS... | 1960 | 959 | False | KINGSTON UPON HULL : ENGLAND | STEVE HAIGH | _SH70_ | 13022 | None | NaN |
| 4 | 2014-09-16 15:05:26 | I'm so mean I make medicine sick | 316 | 421 | True | George | georgehughes77 | 2487 | None | NaN |
create user UTC offset in hours
- for another time, ignore for now (out of scope)
tweets_df['user_utc_offset_hr'] = tweets_df.user_utc_offset / 3600.0
tweets_df['user_utc_offset_hr'].value_counts()
-5.00 11602
-8.00 11190
-6.00 6058
0.00 6021
-7.00 2269
-4.00 2147
1.00 2067
-3.00 872
-10.00 668
-9.00 560
2.00 441
3.00 416
8.00 327
11.00 236
7.00 180
-2.00 165
-11.00 151
9.00 140
6.00 123
4.00 120
10.00 111
5.50 108
5.00 106
13.00 61
10.50 55
5.75 12
3.50 6
4.50 5
-3.50 4
9.50 2
6.50 1
-1.00 1
Name: user_utc_offset_hr, dtype: int64
time index
dates_allTweets = []
for tweet in tweets_data:
try:
dates_allTweets.append(tweet['created_at'])
except:
pass
len(dates_allTweets)
74902
dates_allTweets = tweets_df['created_at'].tolist()
# a list of "1's" to count the tweets
ones = [1]*len(dates_allTweets)
# the index of the series
idx = pd.DatetimeIndex(dates_allTweets)
# the actual series (at series of 1s for the moment)
tweets_KovWard = pd.Series(ones, index=idx)
# Resampling / bucketing
per_minute = tweets_KovWard.resample('1Min', how='sum').fillna(0)
per_minute[(per_minute.index > '2016-11-20 04:30:00') &
(per_minute.index < '2016-11-20 06:00:00')].plot(figsize=(12,6), label='Tweets')
<matplotlib.axes._subplots.AxesSubplot at 0x8d25e48>
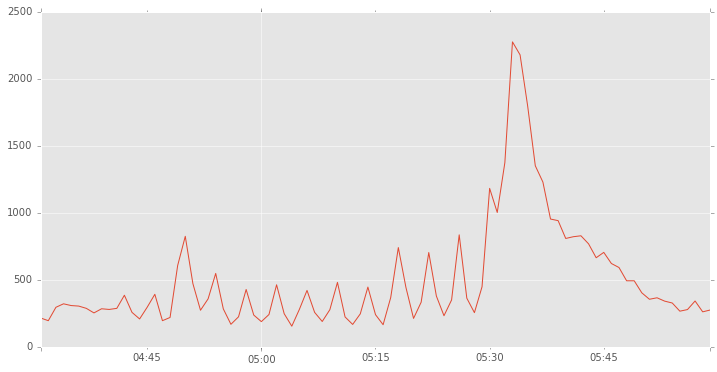
print per_minute[(per_minute.index > '2016-11-20 04:44:00') &
(per_minute.index < '2016-11-20 05:34:00')]
2016-11-20 04:45:00 296.0
2016-11-20 04:46:00 392.0
2016-11-20 04:47:00 195.0
2016-11-20 04:48:00 219.0
2016-11-20 04:49:00 607.0
2016-11-20 04:50:00 825.0
2016-11-20 04:51:00 472.0
2016-11-20 04:52:00 273.0
2016-11-20 04:53:00 358.0
2016-11-20 04:54:00 548.0
2016-11-20 04:55:00 283.0
2016-11-20 04:56:00 168.0
2016-11-20 04:57:00 224.0
2016-11-20 04:58:00 428.0
2016-11-20 04:59:00 237.0
2016-11-20 05:00:00 188.0
2016-11-20 05:01:00 241.0
2016-11-20 05:02:00 463.0
2016-11-20 05:03:00 247.0
2016-11-20 05:04:00 154.0
2016-11-20 05:05:00 280.0
2016-11-20 05:06:00 421.0
2016-11-20 05:07:00 257.0
2016-11-20 05:08:00 189.0
2016-11-20 05:09:00 277.0
2016-11-20 05:10:00 481.0
2016-11-20 05:11:00 223.0
2016-11-20 05:12:00 167.0
2016-11-20 05:13:00 246.0
2016-11-20 05:14:00 446.0
2016-11-20 05:15:00 240.0
2016-11-20 05:16:00 165.0
2016-11-20 05:17:00 368.0
2016-11-20 05:18:00 741.0
2016-11-20 05:19:00 443.0
2016-11-20 05:20:00 212.0
2016-11-20 05:21:00 333.0
2016-11-20 05:22:00 704.0
2016-11-20 05:23:00 379.0
2016-11-20 05:24:00 232.0
2016-11-20 05:25:00 350.0
2016-11-20 05:26:00 836.0
2016-11-20 05:27:00 363.0
2016-11-20 05:28:00 255.0
2016-11-20 05:29:00 448.0
2016-11-20 05:30:00 1183.0
2016-11-20 05:31:00 1003.0
2016-11-20 05:32:00 1375.0
2016-11-20 05:33:00 2277.0
Freq: T, dtype: float64
taking closer look to determine rest period tweets
per_10sec = tweets_KovWard.resample('30S', how='sum').fillna(0)
per_10sec[(per_10sec.index > '2016-11-20 04:45:00') &
(per_10sec.index < '2016-11-20 05:00:00')]
2016-11-20 04:45:30 203.0
2016-11-20 04:46:00 242.0
2016-11-20 04:46:30 150.0
2016-11-20 04:47:00 122.0
2016-11-20 04:47:30 73.0
2016-11-20 04:48:00 85.0
2016-11-20 04:48:30 134.0
2016-11-20 04:49:00 206.0
2016-11-20 04:49:30 401.0
2016-11-20 04:50:00 478.0
2016-11-20 04:50:30 347.0
2016-11-20 04:51:00 264.0
2016-11-20 04:51:30 208.0
2016-11-20 04:52:00 148.0
2016-11-20 04:52:30 125.0
2016-11-20 04:53:00 144.0
2016-11-20 04:53:30 214.0
2016-11-20 04:54:00 317.0
2016-11-20 04:54:30 231.0
2016-11-20 04:55:00 156.0
2016-11-20 04:55:30 127.0
2016-11-20 04:56:00 98.0
2016-11-20 04:56:30 70.0
2016-11-20 04:57:00 80.0
2016-11-20 04:57:30 144.0
2016-11-20 04:58:00 250.0
2016-11-20 04:58:30 178.0
2016-11-20 04:59:00 134.0
2016-11-20 04:59:30 103.0
Freq: 30S, dtype: float64
# rd1: 2016-11-20 04:42:30 - 04:45:30
# rd1 rest: 2016-11-20 04:45:30 - 04:46:30
# rd2 rest: 2016-11-20 04:49:30 - 04:50:30
tweets_df[(tweets_df['created_at'] >= '2016-11-20 04:49:30') & \
(tweets_df['created_at'] < '2016-11-20 04:50:30')]['text'].count()
879
from datetime import timedelta
fight_start_text = '2016-11-20 04:42:30'
fight_start_time = datetime.strptime('2016-11-20 04:42:30', '%Y-%m-%d %H:%M:%S')
rnd = timedelta(minutes = 3)
rst = timedelta(minutes = 1)
rnd_start_stop = []
rst_start_stop = []
for i in range(12):
print 'round %d start: %s' % (i+1, (i*(rnd+rst)+fight_start_time).strftime('%Y-%m-%d %H:%M:%S'))
rnd_start = i*(rnd+rst)+fight_start_time
rnd_stop = rnd_start + rnd
rst_start = rnd_start + rnd
rst_stop = rst_start + rst
rnd_start_stop.append((rnd_start.strftime('%Y-%m-%d %H:%M:%S'), rnd_stop.strftime('%Y-%m-%d %H:%M:%S')))
rst_start_stop.append((rst_start.strftime('%Y-%m-%d %H:%M:%S'), rst_stop.strftime('%Y-%m-%d %H:%M:%S')))
print ''
print rnd_start_stop
print rst_start_stop
round 1 start: 2016-11-20 04:42:30
round 2 start: 2016-11-20 04:46:30
round 3 start: 2016-11-20 04:50:30
round 4 start: 2016-11-20 04:54:30
round 5 start: 2016-11-20 04:58:30
round 6 start: 2016-11-20 05:02:30
round 7 start: 2016-11-20 05:06:30
round 8 start: 2016-11-20 05:10:30
round 9 start: 2016-11-20 05:14:30
round 10 start: 2016-11-20 05:18:30
round 11 start: 2016-11-20 05:22:30
round 12 start: 2016-11-20 05:26:30
[('2016-11-20 04:42:30', '2016-11-20 04:45:30'), ('2016-11-20 04:46:30', '2016-11-20 04:49:30'), ('2016-11-20 04:50:30', '2016-11-20 04:53:30'), ('2016-11-20 04:54:30', '2016-11-20 04:57:30'), ('2016-11-20 04:58:30', '2016-11-20 05:01:30'), ('2016-11-20 05:02:30', '2016-11-20 05:05:30'), ('2016-11-20 05:06:30', '2016-11-20 05:09:30'), ('2016-11-20 05:10:30', '2016-11-20 05:13:30'), ('2016-11-20 05:14:30', '2016-11-20 05:17:30'), ('2016-11-20 05:18:30', '2016-11-20 05:21:30'), ('2016-11-20 05:22:30', '2016-11-20 05:25:30'), ('2016-11-20 05:26:30', '2016-11-20 05:29:30')]
[('2016-11-20 04:45:30', '2016-11-20 04:46:30'), ('2016-11-20 04:49:30', '2016-11-20 04:50:30'), ('2016-11-20 04:53:30', '2016-11-20 04:54:30'), ('2016-11-20 04:57:30', '2016-11-20 04:58:30'), ('2016-11-20 05:01:30', '2016-11-20 05:02:30'), ('2016-11-20 05:05:30', '2016-11-20 05:06:30'), ('2016-11-20 05:09:30', '2016-11-20 05:10:30'), ('2016-11-20 05:13:30', '2016-11-20 05:14:30'), ('2016-11-20 05:17:30', '2016-11-20 05:18:30'), ('2016-11-20 05:21:30', '2016-11-20 05:22:30'), ('2016-11-20 05:25:30', '2016-11-20 05:26:30'), ('2016-11-20 05:29:30', '2016-11-20 05:30:30')]
tweets_df['rest_period'] = 0
rst_prd = 1
for i in rst_start_stop:
tweets_df.loc[(tweets_df['created_at'] >= i[0]) & (tweets_df['created_at'] < i[1]), 'rest_period'] = rst_prd
rst_prd += 1
tweets_df.rest_period.value_counts()
0 67814
2 879
12 861
9 726
11 706
10 632
3 531
1 445
7 440
6 430
5 429
8 415
4 394
Name: rest_period, dtype: int64
tweets_df[tweets_df.rest_period == 1]['text']
11121 Kovalev won round one. Good jab. Ward not very...
11122 RT @RBRBoxing: Retweet if you think Kovalev wi...
11123 UH OH WARD GOT CAUGHT #KovalevWard
11124 RT @amirkingkhan: Let's go @andreward. #Kovale...
11125 #kovalevward @ T-Mobile Arena https://t.co/9vI...
11126 Ward staggering after a jab. Going to change m...
11127 RT @PromoDelPueblo: Vaya combate que nos esper...
11128 RT @TheDKano: Here we go for boxing's pound fo...
11129 RT @amirkingkhan: Let's go @andreward. #Kovale...
11130 RT @AndreasHale: Kovalev’s jab is dominant in ...
11131 Kovalev's armpit is about to be the real winne...
11132 !!!!!!!!!!!!!! Kov starting out strong. Ward n...
11133 RT @SugarRayLeonard: Who will be winning this ...
11134 RT @danrafaelespn: Rd 1 for Kovalev, no questi...
11135 RT @amirkingkhan: Let's go @andreward. #Kovale...
11136 RT @RBRBoxing: Good start, Ward runs into a ha...
11137 Round 1 #KovalevWard : 10-9 Kovalev
11138 Kovalev takes R1 10-9. #KovalevWard
11139 RT @Jeskeliin22: Se viene que peleón, Kovalev ...
11140 Finally people are seeing why I was shocked by...
11141 RT @Main_Events: This is the moment we have al...
11142 Rd. 1: Tough round to score. Largely a feel-ou...
11143 RT @rosieperezbklyn: Oh! Ward stumbled! @HBObo...
11144 Le jab de Kovalev fait le travail. 10-9 Kovale...
11145 RT @danrafaelespn: Rd 1 for Kovalev, no questi...
11146 Fucking Russians!!!! #KovalevWard
11147 Ward was winning 1st round with jab to body, b...
11148 #KovalevWard round 1 kovalev.
11149 That jab rocking Ward. Wow! #KovalevWard
11150 Round 1 to kovalev #KovalevWard
...
11536 RT @boxingcorner247: Here we go #KovalevWard ���...
11537 1st round Kovalev 10-9 #KovalevWard
11538 R1 Ward showing more fight than flight, but ea...
11539 1st round i think goes to Kovalev he landed th...
11540 Ward just needs to be super clever in the figh...
11541 #KovalevWard jordanaharkness @ T-Mobile Arena ...
11542 Kovalev showing his power early with the jab. ...
11543 RT @LennoxLewis: Let's get ready to ruuuuumble...
11544 ウォードさん、コバレフさんのジャブに手こずる。 #KovalevWard
11545 Round 1: Ward appears stunned by Kovalev's pow...
11546 RT @chaka_210: Es para kovalev este round!!! #...
11547 RT @rosieperezbklyn: Good 1st round! Gave it t...
11548 RT @Patrick_Wyman: 10-9 Kovalev in the first. ...
11549 Kovalev wins round 1 for me #KovalevWard
11550 WHOAH CUT THE TENSION WITH A KNIFEEEE. That ja...
11551 Wow. Ward buzzed by a jab already. \n\n#Kovale...
11552 Kovalev 1-0. Ward felt the power and was a lit...
11553 #letsgetreadytorumble #kovalevward https://t.c...
11554 Felt that power already 😏 #KovalevWard
11555 A cautious start, not surprising. First round ...
11556 1-0 Ward #KovalevWard
11557 RT @sand_trevino: This round goes to Kovalev. ...
11558 Ward's face is already showing the results of ...
11559 10-9 Kovalev. #KovalevWard
11560 Kovalev got Ward looking like Sullinger..\n#Ko...
11561 Slow first round. If kovalev keeps leaning on ...
11562 Good start for Sergey Kovalev.\nGood start for...
11563 RT @ChavaESPN: Round 1. Kovalev se ha llevado ...
11564 Round 1de estudio pero se lo doy a Kovalev #Ko...
11565 Both guys understandably cagey in round one bu...
Name: text, dtype: object
calc tw prob/rd
- any rd 2 surprises?
tweets_df[(tweets_df['text'].str.contains(r'\d+\-\d+|round|rd', case=False)) & (tweets_df.rest_period!=0)]\
[['rest_period', 'user_screen_name', 'text']].to_excel('data/scorecard_tweets.xlsx', encoding='utf8')
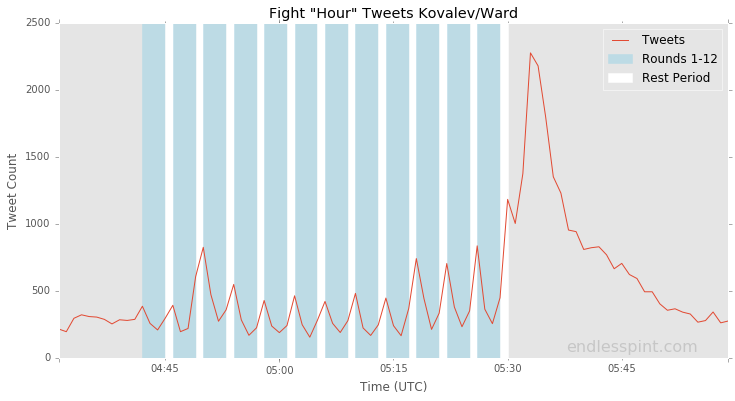
ax = per_minute[(per_minute.index > '2016-11-20 04:30:00') &
(per_minute.index < '2016-11-20 06:00:00')].plot(figsize=(12,6), label='Tweets')
ax.axvspan(rnd_start_stop[0][0], rnd_start_stop[0][1], alpha=0.7, color='lightblue', label="Rounds 1-12")
ax.axvspan(rst_start_stop[0][0], rst_start_stop[0][1], color='white', label="Rest Period")
for i in range(1,12):
ax.axvspan(rnd_start_stop[i][0], rnd_start_stop[i][1], alpha=0.7, color='lightblue')
ax.axvspan(rst_start_stop[i][0], rst_start_stop[i][1], color='white')
plt.title('Fight "Hour" Tweets Kovalev/Ward')
plt.xlabel("Time (UTC)")
plt.ylabel("Tweet Count")
plt.legend(loc='upper right')
ax.text('2016-11-20 05:55:00', 20, 'endlesspint.com',
fontsize=16, color='gray',
ha='right', va='bottom', alpha=0.3)
ax.grid(False, which='both')
### save file localy w high resolution
plt.savefig('img/fight_hour_tweets.PNG', dpi=1200)
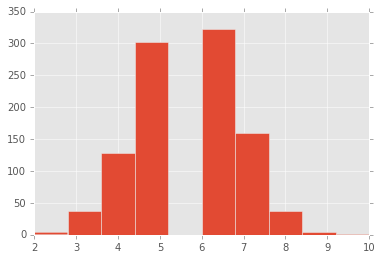
plot hist of rd’s won over 1k sim [nfl/wk8]
- what % of sim agree with judges?
kov_rd_prob = np.array([0.962, 1.000, 0.627, 0.727, 0.293, 0.862, 0.082, 0.075, 0.028, 0.689, 0.082, 0.167])
np.random.seed(506) # "SOG" ~ 506
bouts = 1000
samp_bouts = np.random.random((bouts, len(kov_rd_prob)))
print kov_rd_prob
print samp_bouts[:5]
[ 0.962 1. 0.627 0.727 0.293 0.862 0.082 0.075 0.028 0.689
0.082 0.167]
[[ 0.847888 0.0062996 0.11547329 0.06227527 0.70417491 0.45142321
0.02663976 0.68392883 0.8048215 0.01091125 0.99085692 0.98667746]
[ 0.51372109 0.05352931 0.55695119 0.56343986 0.16066945 0.24419693
0.00722941 0.2815361 0.48279483 0.50589732 0.53835301 0.28329453]
[ 0.27038547 0.49515731 0.86365123 0.46734458 0.73658639 0.62529576
0.44125324 0.47066594 0.27224368 0.37605197 0.34024841 0.95194275]
[ 0.81634129 0.58905575 0.97129374 0.46887292 0.83701569 0.17920073
0.0192533 0.1664162 0.58023702 0.93020315 0.6370348 0.42960779]
[ 0.14706038 0.5908011 0.49457534 0.04813603 0.10570926 0.05762396
0.86765057 0.63971255 0.70860045 0.95180043 0.43166628 0.31270852]]
kov_rd_wins = samp_bouts < kov_rd_prob
kov_rd_wins[:5]
array([[ True, True, True, True, False, True, True, False, False,
True, False, False],
[ True, True, True, True, True, True, True, False, False,
True, False, False],
[ True, True, False, True, False, True, False, False, False,
True, False, False],
[ True, True, False, True, False, True, True, False, False,
False, False, False],
[ True, True, True, True, True, True, False, False, False,
False, False, False]], dtype=bool)
kov_scores = np.sum(kov_rd_wins, axis=1)
print kov_scores[:25]
[7 8 5 5 6 4 6 5 7 5 5 3 4 7 8 3 4 6 5 5 3 6 5 4 9]
plt.hist(kov_scores)
(array([ 4., 38., 129., 303., 0., 323., 159., 38., 4., 2.]),
array([ 2. , 2.8, 3.6, 4.4, 5.2, 6. , 6.8, 7.6, 8.4,
9.2, 10. ]),
<a list of 10 Patch objects>)
df = pd.DataFrame(kov_scores)
ax = df.plot(kind='density', figsize=(12,6), legend=False)
# plt.legend(False)
plt.title('Kovalev Rounds Won (1,000 bouts simulated)')
plt.xlim((0,12))
plt.xlabel('Rounds')
ax.text(11.8, 0.01, 'endlesspint.com',
fontsize=16, color='gray',
ha='right', va='bottom', alpha=0.3)
ax.grid(False, which='both')
### save file localy w high resolution
plt.savefig('img/kov_rnds_won_density.PNG', dpi=1200)
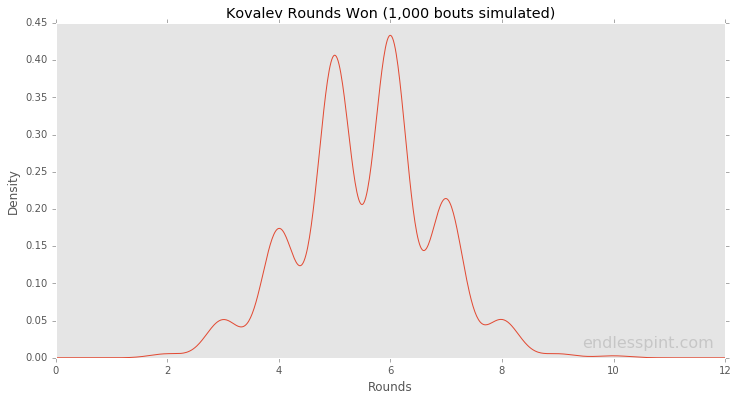
print np.median(kov_scores)
print np.mean(kov_scores)
6.0
5.564
print np.mean(kov_scores <= 5.0)
print np.mean(kov_scores == 6.0)
print np.mean(kov_scores <= 6.0)
0.474
0.323
0.797
len(kov_scores)
1000
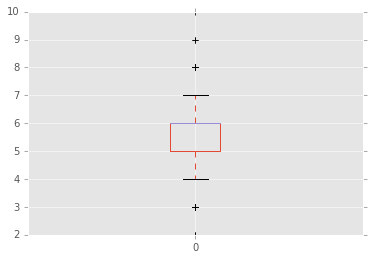
df.describe()
| 0 | |
|---|---|
| count | 1000.000000 |
| mean | 5.564000 |
| std | 1.189672 |
| min | 2.000000 |
| 25% | 5.000000 |
| 50% | 6.000000 |
| 75% | 6.000000 |
| max | 10.000000 |
df.plot(kind='box')
<matplotlib.axes._subplots.AxesSubplot at 0xb6494748>